
Deploy PostgreSQL
Railway offers two PostgreSQL deployment options to accommodate different needs: a Standalone Instance and a High Availability (HA) Cluster.
-
Standalone Instance - a single Postgres database server that is easy to manage; ideal for development environments, smaller projects, or services which are less sensitive to disruption.
-
High Availability (HA) Cluster - intended for production workloads where uptime is critical. It consists of three Postgres nodes in replication mode managed by Repmgr, complemented by a Pgpool-II proxy service.
Standalone PostgreSQL
Let's talk about how to deploy, connect, and manage the standalone instance.
Deploy
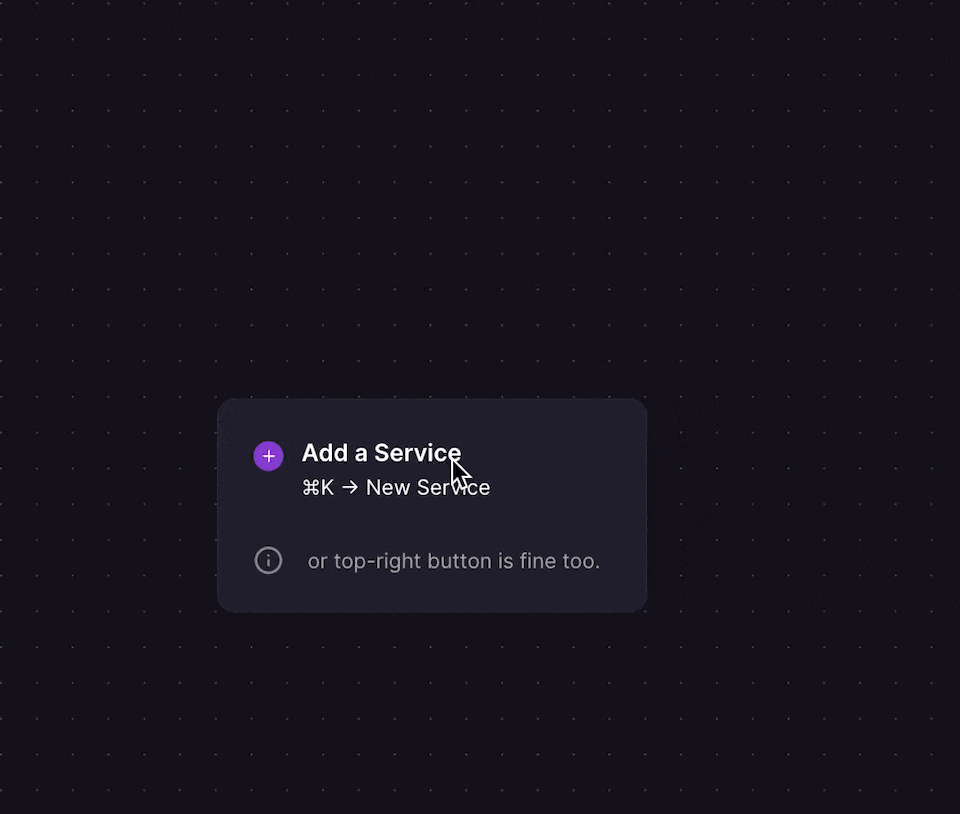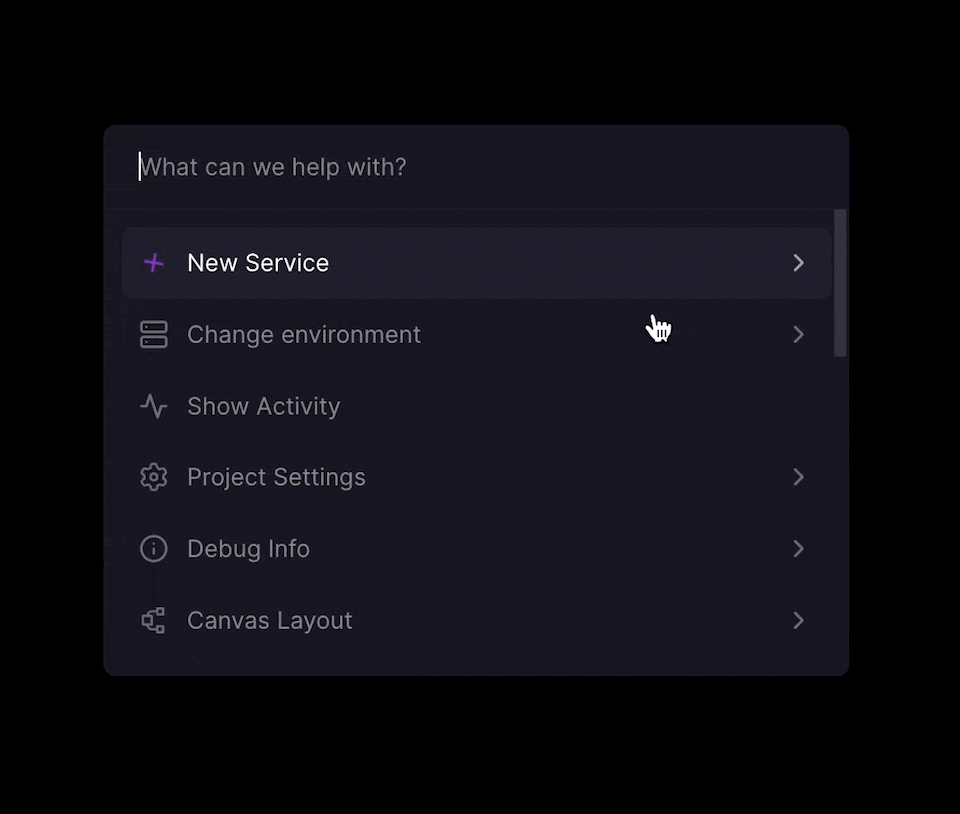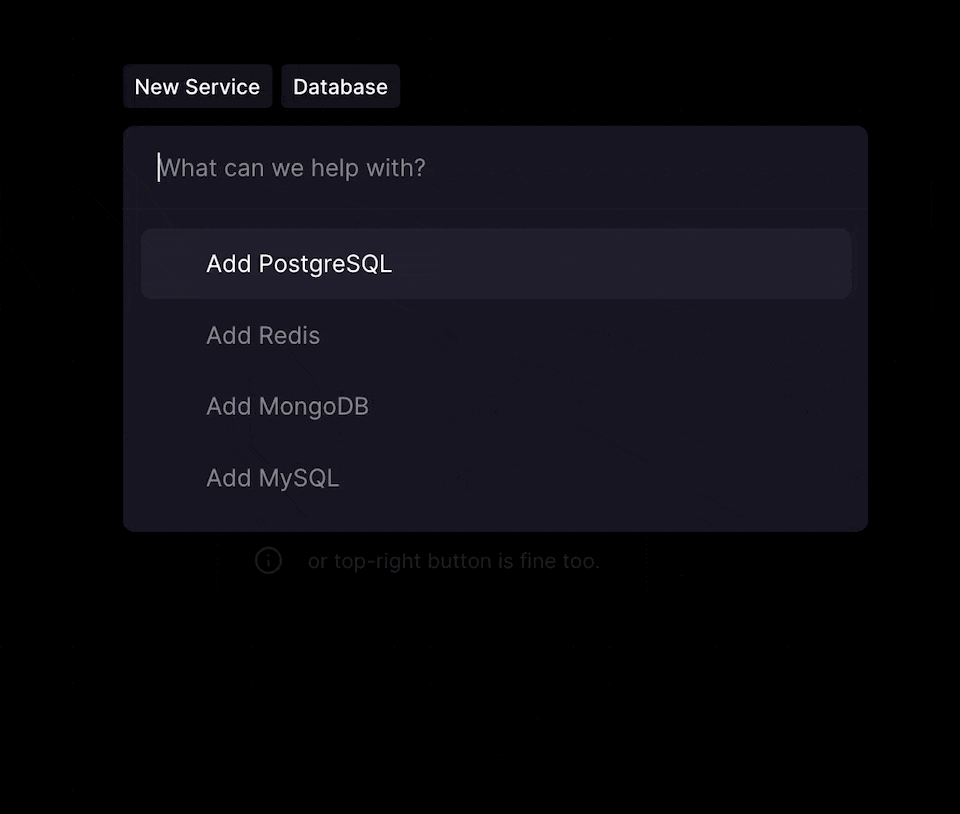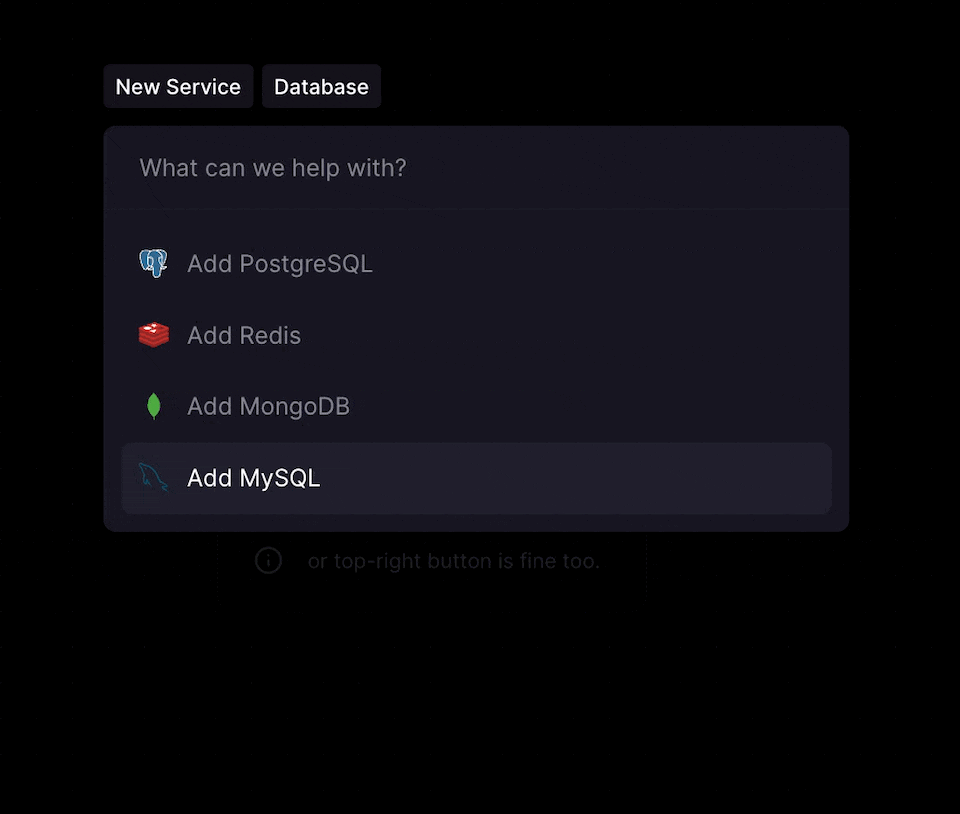
You can deploy a standalone PostgreSQL database via the CMD + K menu or by clicking the + New button on the Project Canvas.
You can also deploy it via the template from the template marketplace.
Deployed Service
Upon deployment, you will have a standalone PostgreSQL service running in your project, deployed from Railway's SSL-enabled Postgres image, which uses the official postgres image in Docker Hub as its base.
Connect
Connect to the PostgreSQL server from another service in your project by referencing the environment variables made available in the PostgreSQL service:
PGHOSTPGPORTPGUSERPGPASSWORDPGDATABASEDATABASE_URL
Note, Many libraries will automatically look for the DATABASE_URL variable and use
it to connect to PostgreSQL but you can use these variables in whatever way works for you.
Connecting Externally
It is possible to connect to PostgreSQL externally (from outside of the project in which it is deployed), by using the TCP Proxy which is enabled by default.
Keep in mind that you will be billed for Network Egress when using the TCP Proxy.
Modify the Deployment
Since the deployed container is based on an image built from the official PostgreSQL image in Docker hub, you can modify the deployment based on the instructions in Docker hub.
We also encourage you to fork the Railway postgres-ssl repository to customize it to your needs, or feel free to open a PR in the repo!
High Availability PostgreSQL Cluster
We'll cover how to deploy, connect, and manage the High Availability (HA) PostgreSQL cluster in this section.
Deploy
You can deploy a HA PostgreSQL cluster via the template in the marketplace.
Deployed Services
Upon deployment, you will have a cluster of 3 PostgreSQL nodes deployed from the bitnami/postgres-repmgr image, running in replication mode and managed by repmgr.
You will also have a Pgpool-II service deployed from the bitnami/pgpool image which is intended to be used as a proxy to the cluster.
Multi-region Deployment
By default, each node is deployed to a different region (US West, US East, and EU West) for fault tolerance.
Since region selection is a Pro-only feature, this only applies to Pro users. If you deploy this template as a Hobby user, all nodes will deploy to US West.
Connect
You should connect to the cluster via a proxy service which is aware of all of the cluster nodes. We have included a Pgpool-II service in the template deployment for this purpose.
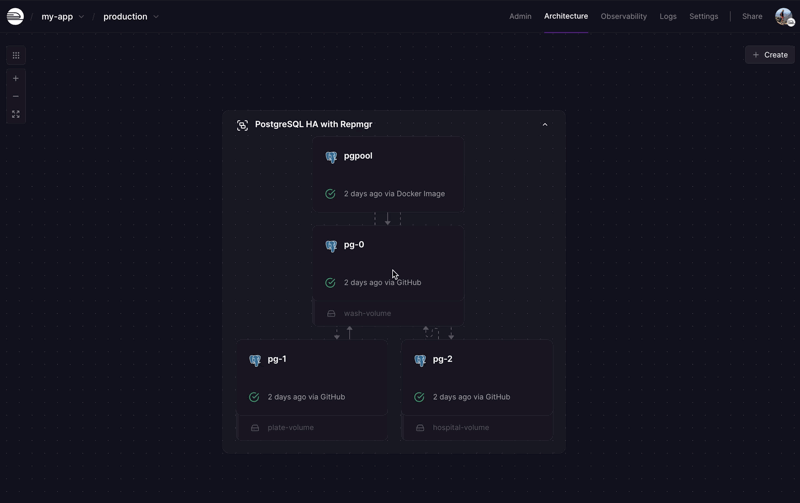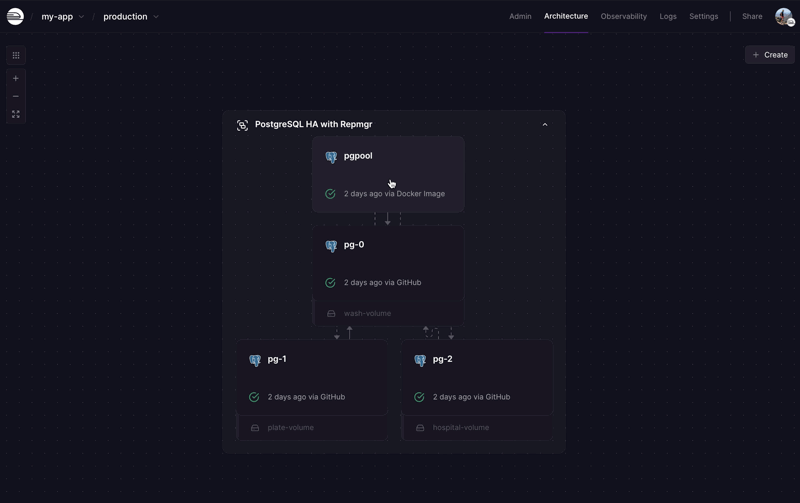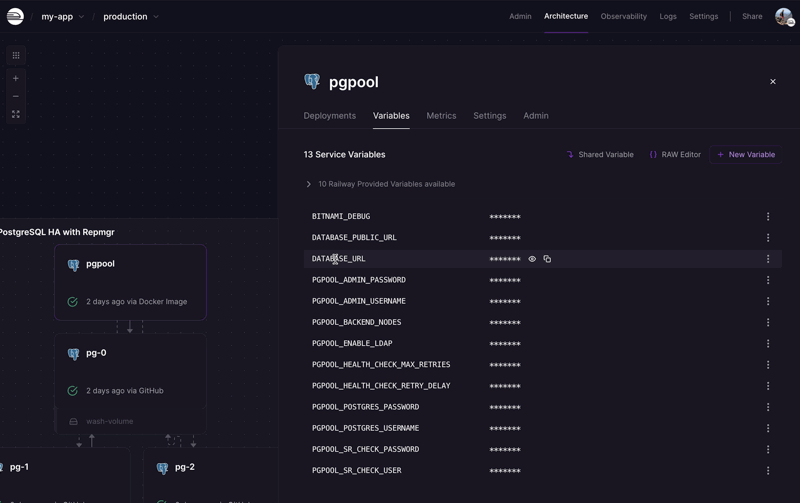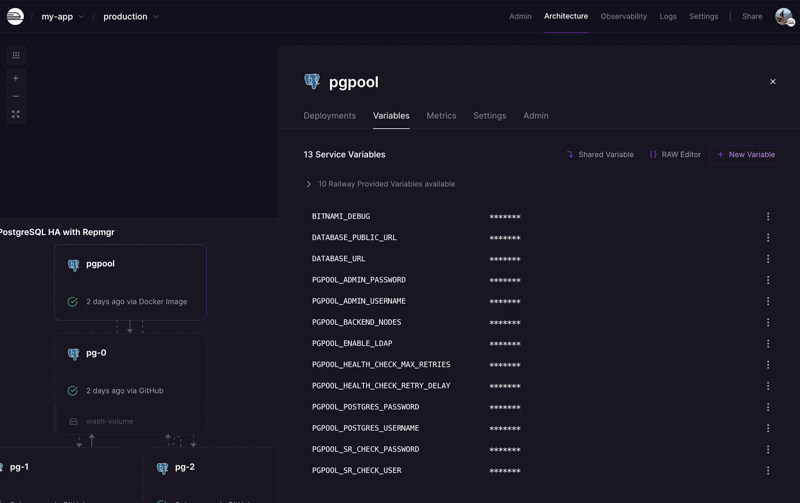
Connect to the cluster via Pgpool by referencing the environment variable DATABASE_URL available in the Pgpool service.
Connecting Externally
It is possible to connect to the PostgreSQL cluster externally (from outside of the project in which it is deployed), by using the TCP Proxy. To do so, you should reference the DATABASE_PUBLIC_URL environment variable available in the Pgpool service.
Keep in mind that you will be billed for Network Egress when using the TCP Proxy.
Modify the Deployment
Since the containers are deployed from bitnami images, you can reference the documentation for each, to understand how to customize them:
Backups and Observability
Especially for production environments, performing regular backups and monitoring the health of your database is essential. Consider adding:
-
Backup solutions: Automate regular backups to ensure data recovery in case of failure. We suggest reviewing the popular PostgreSQL S3 backups template as an example.
-
Observability: Implement monitoring for insights into performance and health of your databases. If you're not already running an observability stack, check out these templates to help you get started building one:
Extensions
In an effort to maintain simplicity in the default templates, we do not plan to add exentions to the PostgreSQL templates covered in this guide.
For some of the most popular extensions, like PostGIS and Timescale, there are several options in the template marketplace.
Additional Resources
While these templates are available for your convenience, they are considered unmanaged, meaning you have total control over their configuration and maintenance.
We strongly encourage you to refer to the source documentation to gain deeper understanding of their functionality and how to use them effectively. Here are some links to help you get started:
Edit this file on GitHub